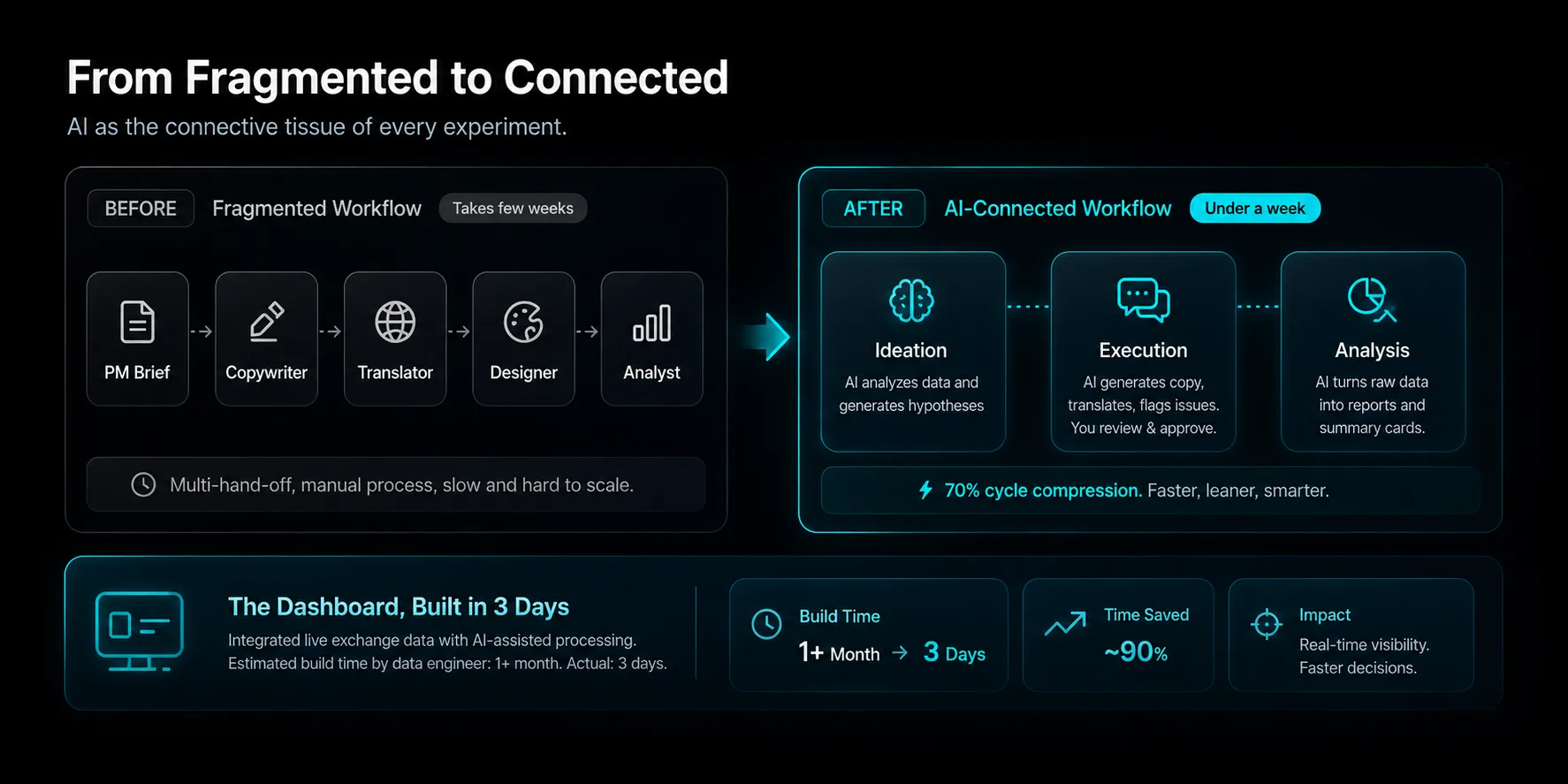
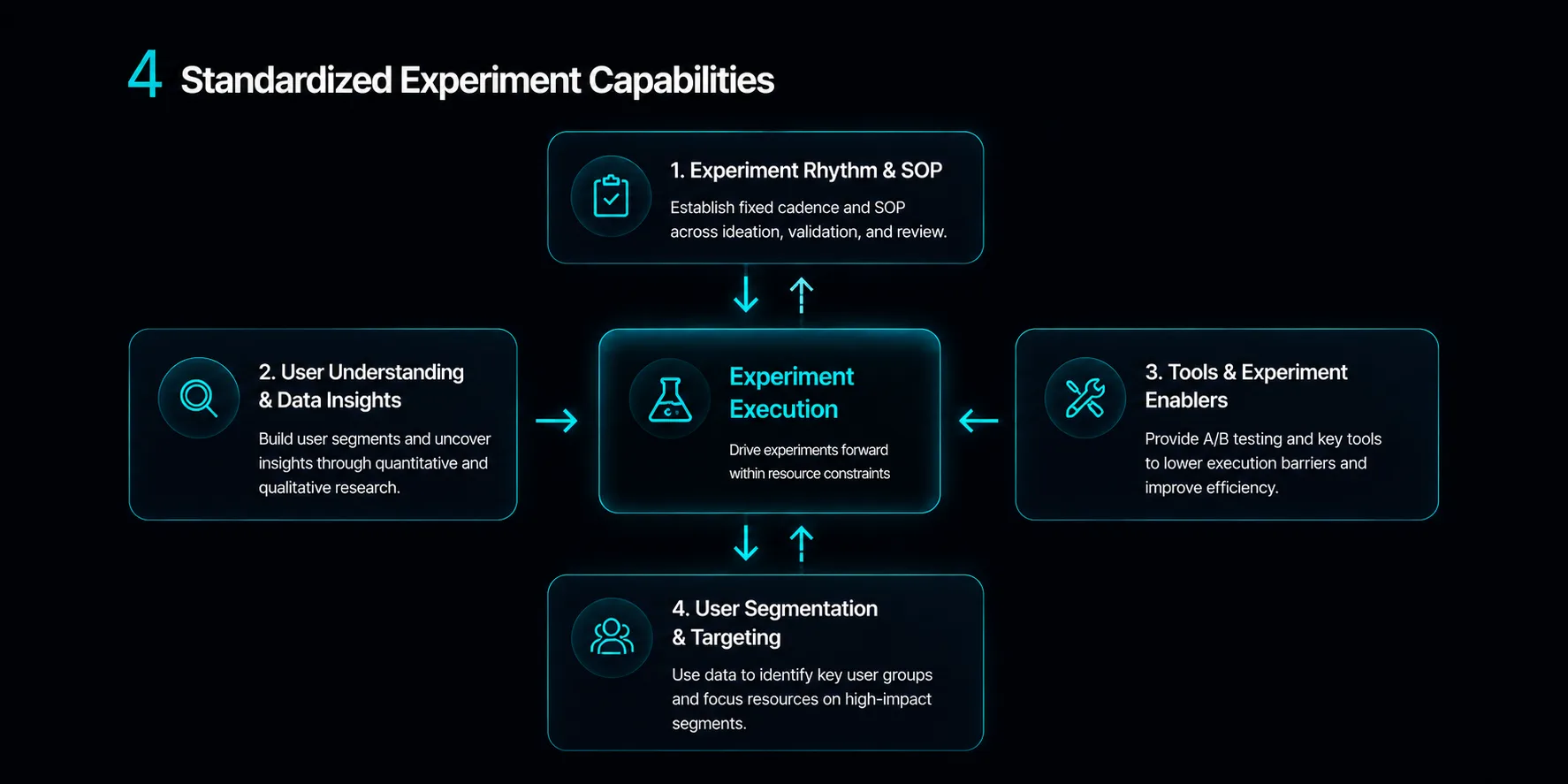
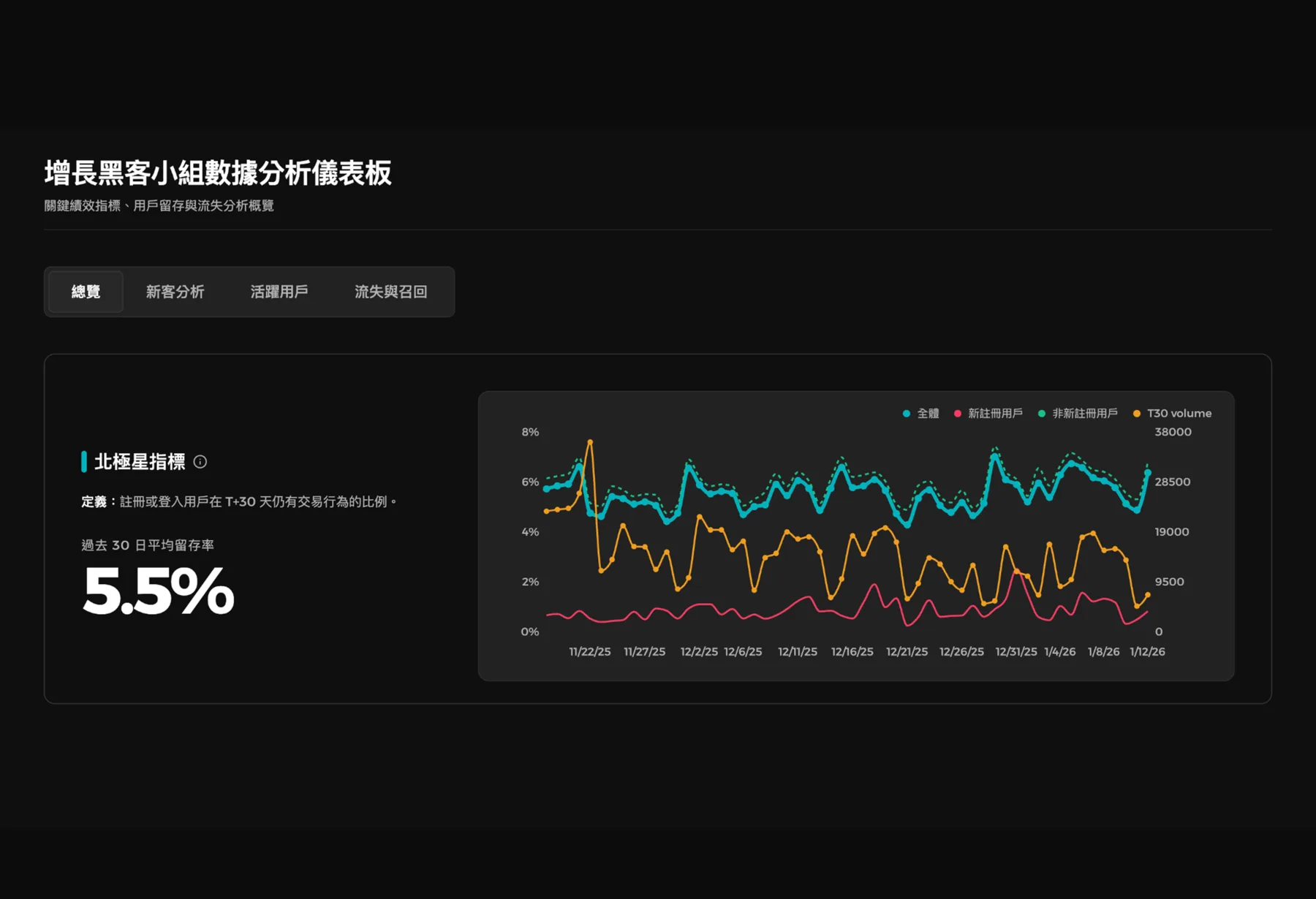
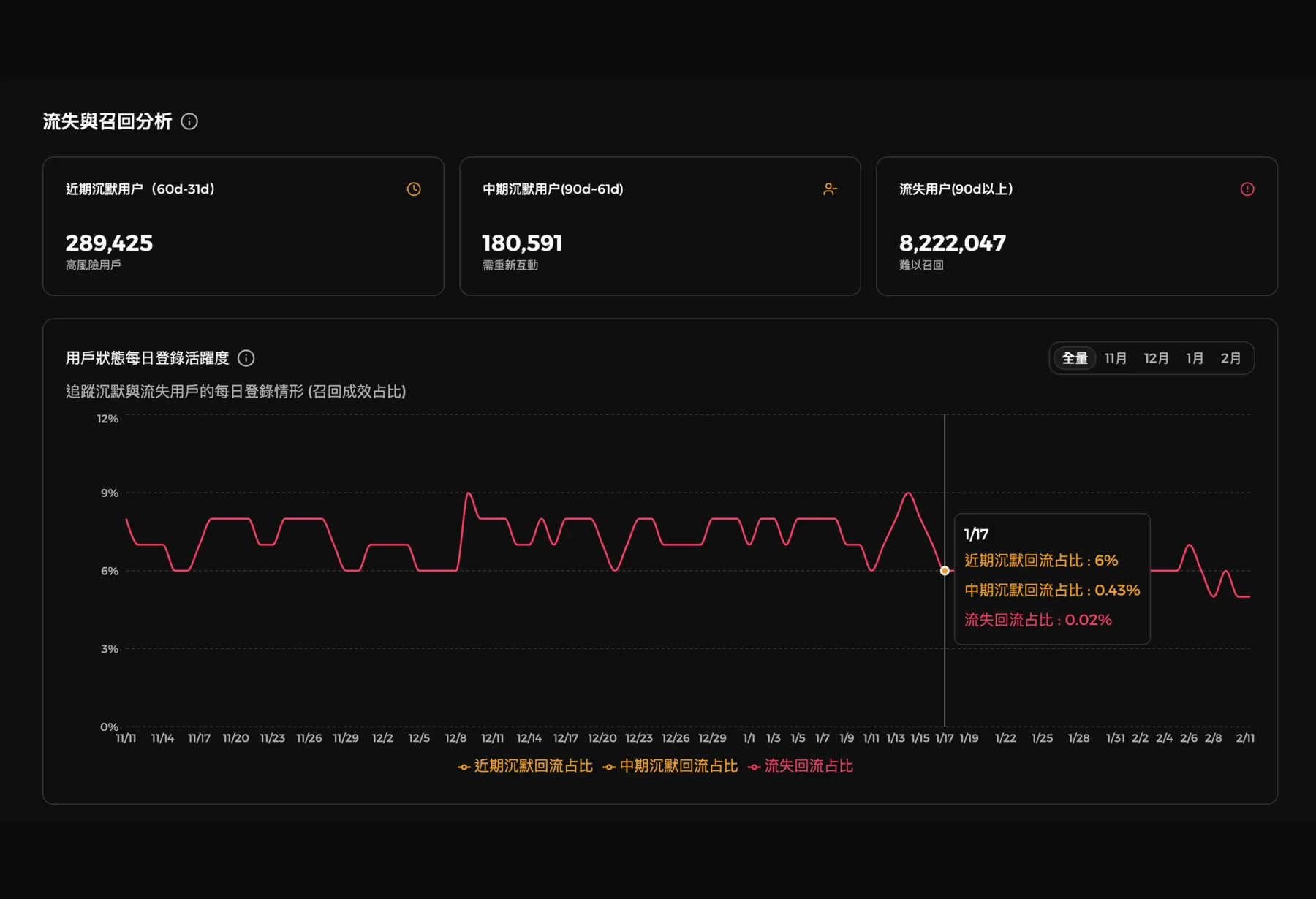
Defining the growth hacker role at BitMart
BitMart already had a growth team and a product team. What it didn't have was a dedicated experimentation function — someone whose job was to test growth hypotheses fast, validate which levers actually move activation and retention, then hand the proven ones back for the operating teams to scale. I joined as the first growth hacker to build that function — with no experiment platform, no A/B framework, no dashboard, and a deliverable that wasn't campaigns but validated growth models.
Before designing experiments, I spent the first weeks running 1-on-1s across product, growth, and operations teams, and shipping a foundational user survey to understand who BitMart's users actually were. The output wasn't a number to report — it was the user segmentation that anchored every experiment that followed: new users, active users, and at-risk-of-churning users.
The function started as one person. I led the strategy while running execution myself, and the supporting roles I needed — engineering, operations, product coordination, analyst support — all sat in other teams. None of them reported to me. Shipping experiments meant building cross-functional influence, not headcount. As the cadence proved its value, full-time hires joined and the function grew into a small dedicated team.
- Hats I wore at the start: Team Lead, UX Designer, UI and Visual Designer, Data Analyst — five roles, one person
- Functions I coordinated without authority: Backend engineering, frontend development, product-team alignment, ad-hoc analyst support — none of them reported to me